Как проработать семантическое ядро с помощью Key Collector. Часть 2
В первой части статьи мы рассказали, как придумать маски при сборе семантического ядра, перенести их в программу Key Collector и начать парсинг. Программа на сегодня: очищаем ядро от стоп-слов, группируем и переносим данные обратно в Excel. На выходе — готовое семантическое ядро.

Минусовка
Работать с группой — значит отминусовать её (избавиться от ненужных и нерелевантных стоп-слов) и сгруппировать. Рассмотрим вопрос минусовки. В Key Collector есть «окно стоп-слов», которое позволяет:
- редактировать слова, например, фиксировать их словоформу;
- создавать списки и отправлять каждое минус-слово в свой список;
- отмечать фразы, содержащие стоп-слова.
Сперва отмечаем галочкой слово «купить» (в Key Collector автоматический выделяются все фразы, содержащие «купить»), а затем их удаляем:
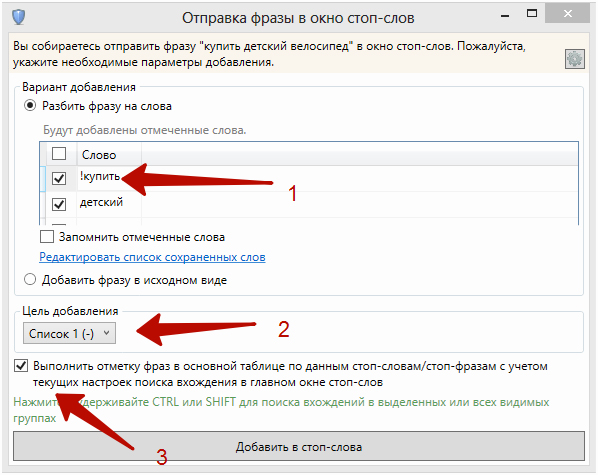
Слова можно закинуть в окно стоп-слов разными способами.
Первый. Отправляем фразы по одной. Это точечный подход, и используется он редко. Кликните по значку щита слева от нужной фразы, чтобы отправить её в окно стоп-слов:
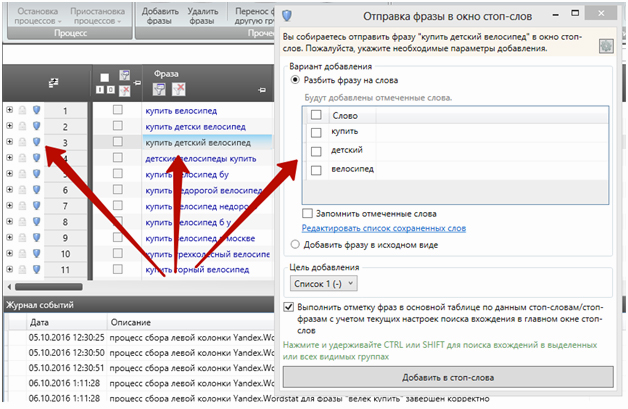
Второй способ. Выделяем группу запросов и жмём «Отправить в окно стоп-слов». Подход уже более массовый, но всё ещё не очень удобный.
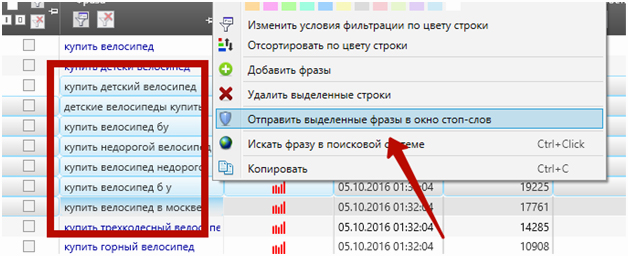
Третий способ. Самый удобный и в то же время массовый — минусовка через анализ групп. Для этого выбираем нужную группу и во вкладке «Данные» заходим в «Анализ групп»:
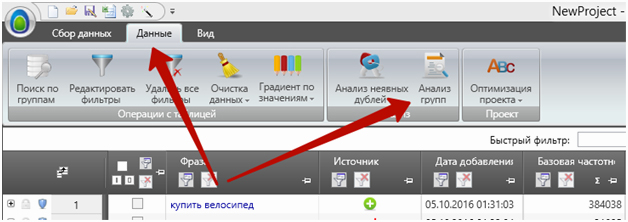
Анализ групп — очень крутой инструмент. Советую потратить 10 минут, чтобы изучить все его возможности: поиграть с различными типами группировки (не забывайте про кнопку «Вычислить группировку»), посмотреть, как работает экспорт (он пригодится, например, для составления отчёта о чистоте трафика).
Для минусовки выбираем тип группировки «по отдельным словам»:
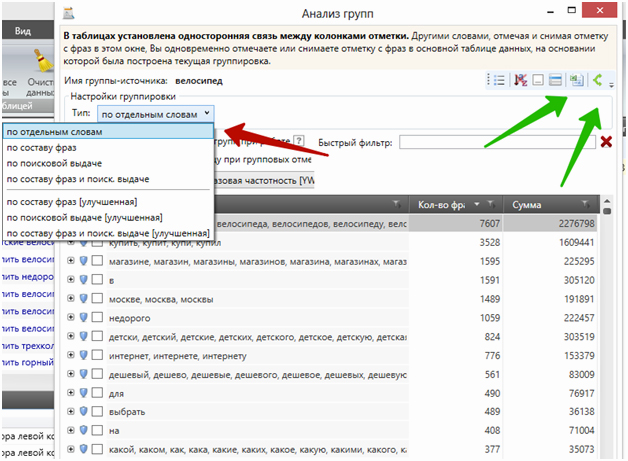
В этой группировке Key Collector разбивает всё семантическое ядро и группирует его по словам, имеющим одинаковую исходную словоформу.
В колонке «Количество фраз» показано, в скольких фразах ядра встречается то или иное слово. В «Сумме» — сумма значений для сгруппированных слов из выбранной вами колонки. Колонки «Количество фраз» и «Сумма по частотности» помогают оценить «опасность» каждого минус-слова. Понятно, что опаснее те, которые встречаются в большом количестве фраз с большой частотностью.
Чтобы начать минусовать, сортируем список по убыванию количества фраз (так удобнее, через пару строк покажу, почему) и начинаем закидывать в окно стоп-слов нерелевантные:
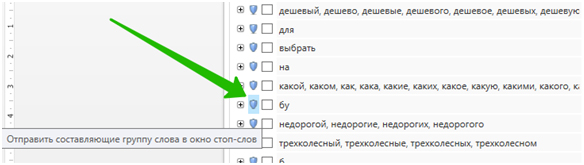
Если вы выберете указанные ниже настройки, то при отправке слова в минус-список в вашей группе галочками отметятся все фразы, содержащие этот минус:
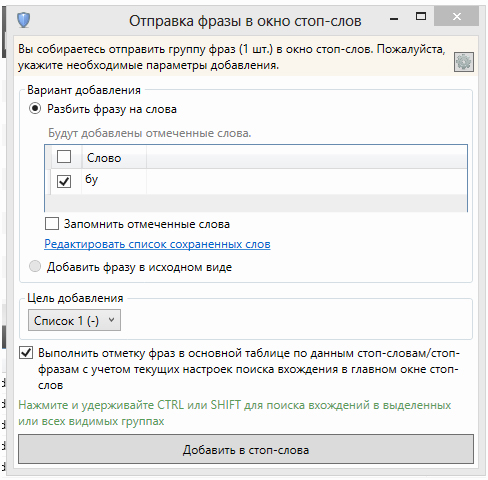
Это удобно, если вам нужно немного ускорить процесс минусации, причём вы можете заминусовать сразу несколько слов, которые содержатся в большом количестве фраз. Именно поэтому мы сортируем список по количеству фраз. В данном примере я добавил в минуса три первых нерелевантных слова — а в таблице выделились сразу 1257 нерелевантных фраз:
Теперь мы можем удалить эти фразы и заново запустить анализ групп.
Таким образом, за 20 секунд мы на 15% уменьшили количество фраз, с которыми нам предстоит работать. Это ускоряет процесс, но сказывается на качестве минусовки. Ведь внутри тех 1200 фраз, которые мы выделили и удалили, могли сидеть другие минуса (их мы теперь не увидим).
Пример: мы не уверены, стоит ли минусовать слово «ручка»:

Мы можем расхлопнуть группу и посмотреть, в каких фразах используется это слово:
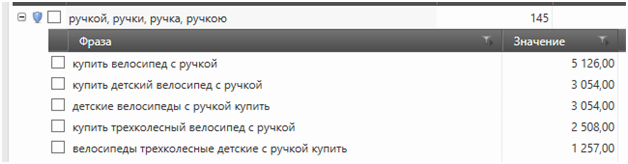
Ага, велосипеды с ручкой — это детские велосипеды, у которых есть ручка, видимо, чтобы родители могли катать своих детей. Однако на сайте у нас в принципе нет раздела с детскими велосипедами. Закидываем «ручки» в минуса.
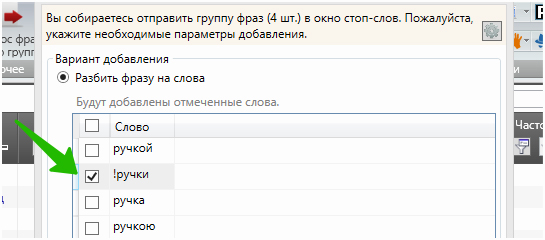
Бывает и так, что одна форма слова является минусом, а другая — нет. Благо, при клике по щиту в окно стоп-слов отправляются все словоформы, причём мы их можем редактировать. В данном случае — приписать восклицательный знак и отправить в минуса только одну словоформу:
То есть мы проходимся по всему списку слов в «Анализе групп» и выбираем минуса. Если у нас мало времени, можем ограничиться какими-то порогом. Например, минусовать до частотности 10.
Кстати, если мы не удаляли фразы по ходу, под конец анализа в списке будут выделены все фразы, содержащие минус-слова. Мы можем удалить их, а можем перенести в отдельную группу для мусорных слов:
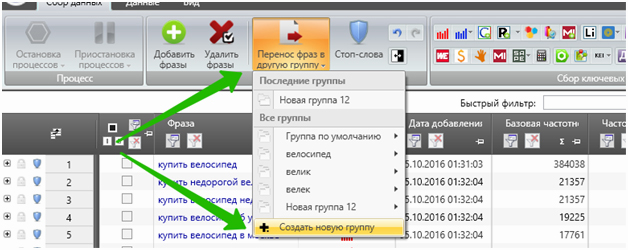
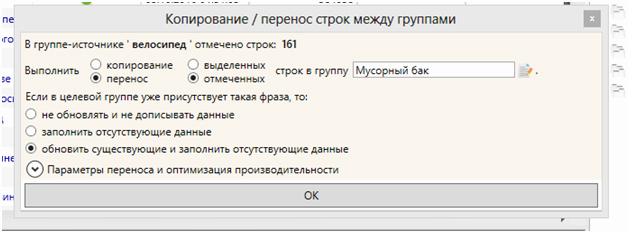
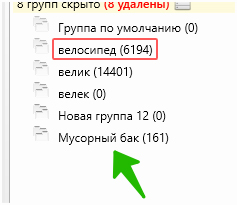
Это удобно, если вы собираетесь добирать дополнительную семантику в тот же проект, пользуясь настройкой «Не добавлять фразу, если она уже есть в какой-то другой группе». Тогда вам не придётся повторно анализировать фразы, которые вы уже обработали.
Сам же полученный список минус-слов можно экспортировать как и куда угодно:
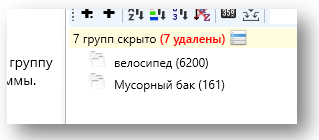
Итак, мы отминусовали группу «Велосипед», переходим к группе «Велик». Эта группа масок оказалась супермусорной! Оказывается, велик — это не только сленговый синоним велосипеда, но и словоформа «большого». Поэтому вместе с масками типа «купить велик» и «заказать велик» подобрались и фразы «купить большой», «заказать большой».
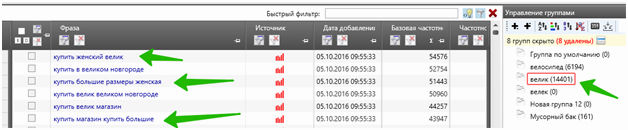
Из-за этого у нас почти 15 тысяч слов всякой фигни. Прикиньте, если бы мы изначально собирали все маски в одну группу, а не разбивали на подгруппы! Пришлось бы вычищать эти 15 тысяч среди всех собранных фраз. Но, к счастью, мы придерживались правила «если ядро незнакомое, и ты не знаешь, как поведут себя маски, раскидай их на парсинге по разным группам». Поэтому сейчас просто удалим группу «велик» и заново соберем её, зафиксировав словоформу «!велик».
«И настроение улучшилось» ©Минусация через анализ групп — это очень удобный способ, который здорово ускоряет процесс. Вам не надо копаться в списке из всех фраз на 7000 строк — достаточно просмотреть группу на 1500 строк.
P. S.
И ещё пара мыслей в тему минусации. В начале статьи мы говорили о том, что иногда удобно отправлять на парсинг маски, уже уточненные минус-словами.
В KC есть возможность сформировать список минусов на уровне инструмента «Стоп-слова» и использовать его при составлении запроса к Wordstat.

Если активировать эту функцию, то в списке для парсинга будет отображаться, например, «купить велосипед», а в Wordstat отправится расширенный запрос вида «купить велосипед -бу -детский».
Итого, если вы уже на входе знаете нежелательные для себя слова — применяйте их при составлении запроса. Составить список минусов до начала парсинга можно руководствуясь личным опытом, интуицией, здравым смыслом или готовыми списками.
Группировка
После того, как у нас готово чистое отминусованное ядро, его нужно группировать.
Группировка — это распределение слов по группам (по-умному называется «кластеризация»). Далее можно написать под каждую группу слов свой вариант объявления. Или — вы решите написать одно объявление для всего ядра, но сгруппированные фразы всё равно раскидать по разным группам объявлений. Или — каждой группе слов прописать объявление, а потом всё это дело раскидать по принципу «один ключевик — одно объявление». Впрочем, это самый долгий способ.
Чаще всего мы раскидываем слова по разным группам и прописываем каждой своё объявление. Однако решение, как именно дробить ядро, зависит только от вас. Два основных ограничения, которые можно использовать — это максимальное/минимальное число слов в группе плюс максимальная/минимальная частотность слов.
Мы уже познакомились с инструментом Key Collector «Анализ групп». Он помогает не только при минусовке, но и при группировке. Ниже я опишу алгоритм, по которому мы группируем слова через анализ групп. Возможно, он кажется слишком замороченным, но жизнь вообще штука тяжёлая.
Сперва нужно понять, стоит ли «сливать» в одну собранные группы. То есть является ли нынешняя разбивка по группам для парсинга равносильной первому этапу семантической группировки. Ведь группы для парсинга мы разбивали, чтобы не нарваться на ситуацию, как со словом «велик». На данном этапе логика разбивки по семантическим группам может измениться.
Что мы имеем:

Три группы: велосипед, велик, велек.
Чего я хочу добиться группировкой: разбить слова на группы, которым затем пропишу индивидуальные объявления с максимальным вхождением ключевых слов в заголовок. Получается, что названия семантических групп должны содержать слова, которые я затем использую в заголовке.
Буду ли я использовать в заголовках слова «велек» и «велик»? Нет, здесь я поступлюсь вхождением, но сделаю объявления более естественным. Для фраз «купить велек» напишу заголовки «Купить велосипед». В данном случае «велек» и «велик» — группы не семантические, потому я не буду использовать в объявлениях слова из названий этих групп.
Итого: в этом случае нужно «слить» все группы в одну, а затем переразбить на группы по другой логике.
Сделаем это:
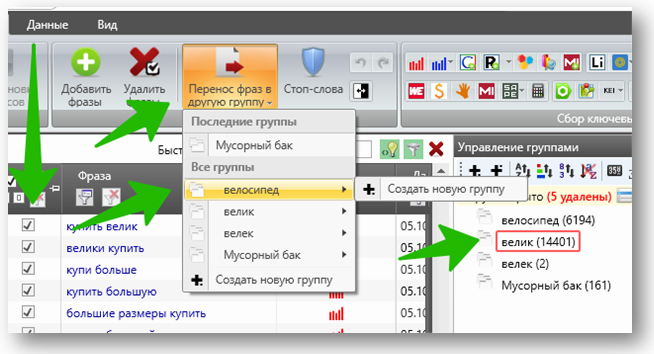
Теперь необходимо узнать реальные частотности полученного списка слов — эта информация нам пригодится позже.
По идее, при парсинге масок мы уже получили частотности слов:
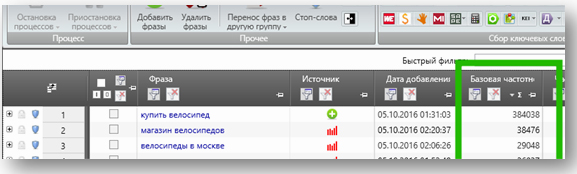
С ними можно работать, но здесь частотности по многим словам завышенные, ведь список не откроссминусован. Давайте пойдём по хардкору: скопируем этот список, откроссминусуем, зальём заново и соберём реальные частотности.
Копируем ключевики:
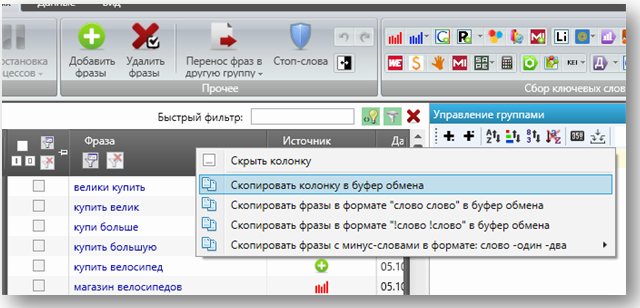
Проводим кроссминусовку:
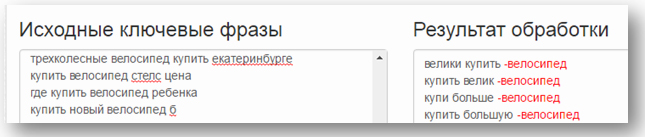
Удаляем старый список слов, добавляем откроссминусованный (не забудьте убрать символ «-" в настройках парсинга):
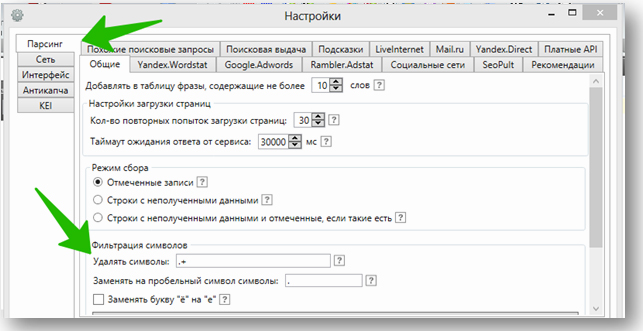
Кстати, это очень полезная настройка, так как вы можете парсить сразу уточнённые ВЧ-минусами фразы — и тем самым экономить время. То есть вместо списка
«велосипед москва»
«велосипед купить»
…
отправлять на парсинг
«велосипед москва -б -у -бу -авито -прокат»
«велосипед купить -трехколесный -б -у -бу»
…
Таким образом, получаем список для парсинга частотности:

Частотность парсится с помощью инструмента «Сбор с Yandex. Direct»:
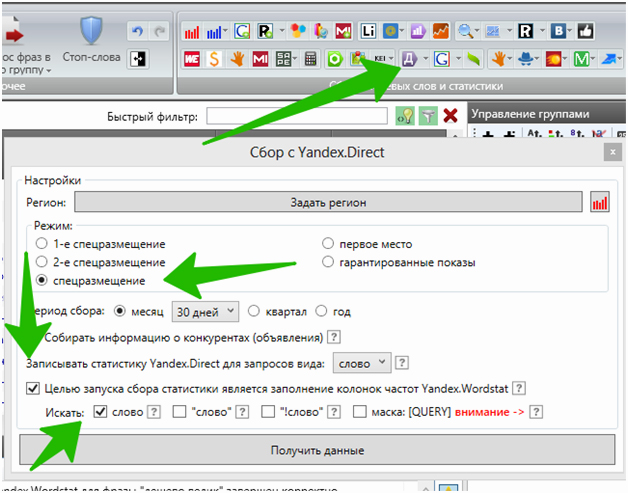
После получения частотностей приступаем к группировке. Для этого нужно определиться с глубиной группировки и порогом высокочастотности (ВЧ).
Порог ВЧ — частота, начиная с которой мы считаем слово высокочастотным. Это нужно для того, чтобы выделить ВЧ-слова в отдельные группы. В конкретном примере подразумеваем под ВЧ ключевик с 300+ показами в месяц (хотя это может быть и 1000, и 5000 — зависит от ситуации).
Глубина группировки определяет, насколько подробно мы разбиваем группы на подгруппы. Также это порог, после которого слова уже не нужно выделять в отдельную группу. В нашем примере возьмём глубину от двух слов и от 30 показов в месяц (в сумме по группе).
Начнём. Выбираем исходную группу, заходим в анализ групп, сортируем по убыванию количества фраз:
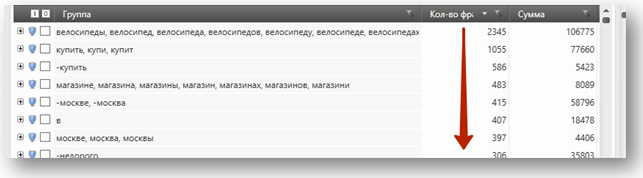
Обратите внимание: сейчас в анализ групп попали минус-слова — с ними на данном этапе не работаем.
Начинаем двигаться сверху вниз по первому кругу, выделяя в отдельные группы фразы с общим «продуктовым» признаком (белые велосипеды, трёхколесные велосипеды, велосипеды в москве, велосипеды недорогие). На втором круге мы будем выделять в группы фразы с «непродуктовыми» добавками (велосипеды купить, магазин велосипедов).
У «продуктовых» добавок больший приоритет, так как они определяют посадочную страницу и вероятнее включаются в заголовок объявления (из ключевика «купить детский трёхколесный велосипед» на 37 символов мы возьмём в заголовок «Детские трёхколесные велосипеды»).
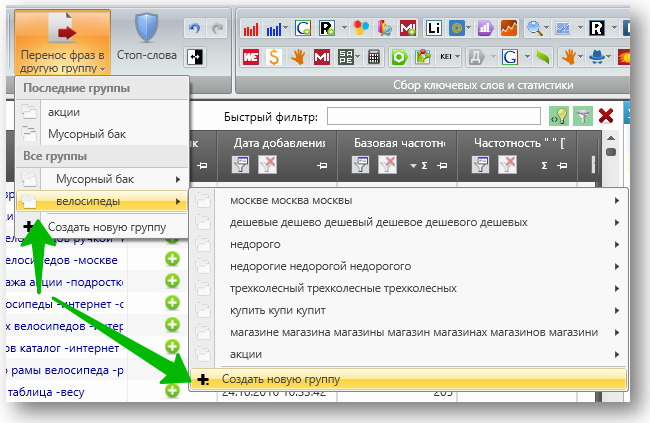
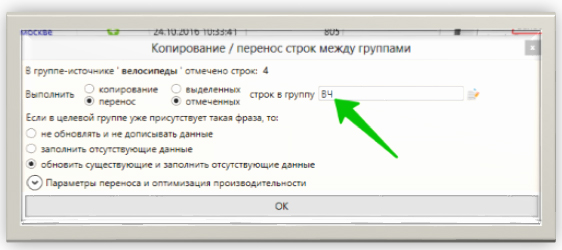
Выделяем группу слов и переносим её в новую группу:
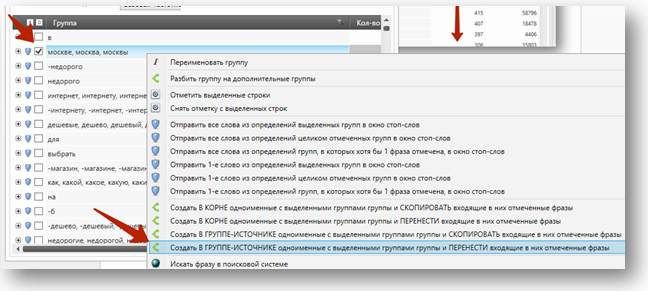
Вуаля, в исходной группе создана подгруппа, в которую перенеслись все фразы, содержащие слово «Москва» и его словоформы:
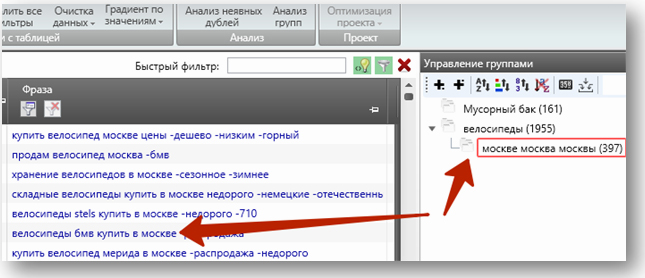
Так мы проходимся сверху вниз, выделяя группы, содержащие от двух слов и 30 показов. Например, выделим группу «велосипеды мужчины»:

Но при этом не станем выделять «велосипеды склад» (не хватает частотности):

Также не будем выделять «велосипеды кама» (не хватает количества фраз в группе). Возможно, пример с «камой» не самый удачный, так как этой фразе можно написать объявление с суперрелевантной посадочной. Но на то он и пример.

После того как мы выделили все «продуктовые» группы, переходим на второй «непродуктовый» круг. После его завершения получим иерархию с первым уровнем вложенности. Это исходная группа и подгруппы — «велосипеды москва», «велосипеды недорого» и т. д.
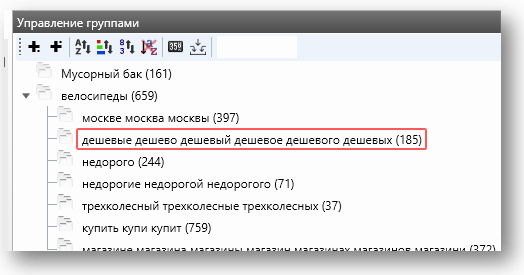
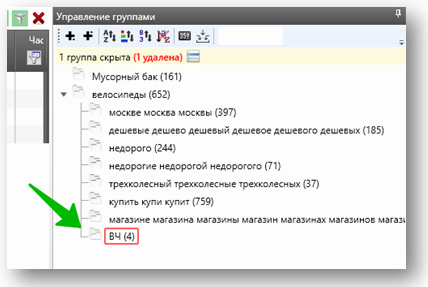
После этого необходимо выделить группу ВЧ-слов. Дело в том, что после первых двух кругов в исходной группе «велосипеды» остались слова, которые не попали ни в одну из подгрупп. Но среди них есть ВЧ, под которые нужно написать индивидуальные объявления. Выделим их в отдельную подгруппу и назовем её «велосипеды_ВЧ». Как и условились ранее, под ВЧ мы подразумеваем фразы от 300 показов:
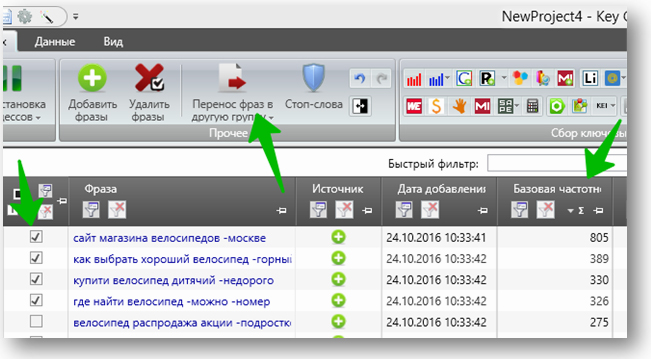
Окончательный список подгрупп на первой ступени иерархии выглядит так:
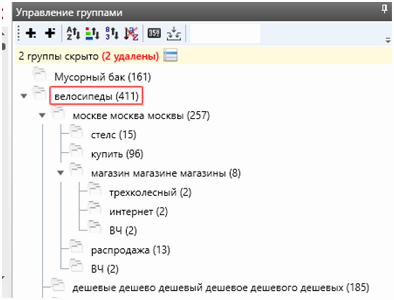
Далее повторяем те же шаги, с теми же ограничениями, но уже на уровне подгрупп. И так несколько раз. То есть после полной группировки у нас получается иерархическая структура семантического ядра с большим уровнем вложенности.
- Исходная группа «велосипеды» разбивается на «велосипеды москва», «велосипеды купить», «велосипеды ВЧ».
- «Велосипеды москва» разбивается на «велосипеды москва магазин», «велосипеды москва стелс», «велосипеды москва ВЧ».
- «Велосипеды москва магазин» — на «велосипеды москва магазин интернет».
Окончательная иерархия выглядит как-то так:
Для удобства можно цветом отмечать группы и подгруппы, которые вы уже полностью проработали:
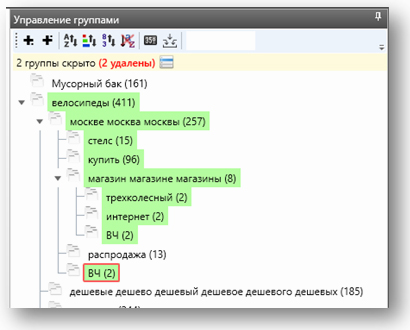
Перенос сгруппированного ядра в Excel-файл
После того как мы проработали всю иерархию — когда она «полностью зелёная», — нужно перенести её в Excel для создания заливочного файла.
К сожалению, в Key Collector нет опции, позволяющей разом выгрузить все ключевики с сохранением структуры в том виде, в котором нам это нужно (ну, или я плохо искал). Придётся работать в «ручном» режиме.
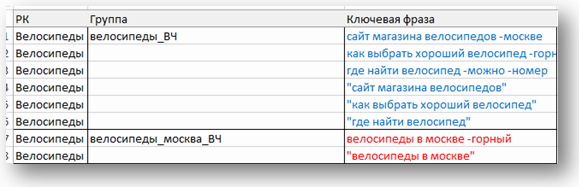
Здесь всё просто: берём по очереди каждую группу из нашей иерархии, копируем ключевики и вставляем в Excel. Группы в Excel называем в соответствии со структурой ядра:
При переносе ВЧ-групп мы обычно дублируем фразы в точном соответствии:

Для массового добавления операторов точного соответствия можно использовать интернет-сервисы или формулы в Еxcel. Для массового удаления минус-слов — инструментом Еxcel «Найти и заменить» (найти «-*" и заменить на " «).
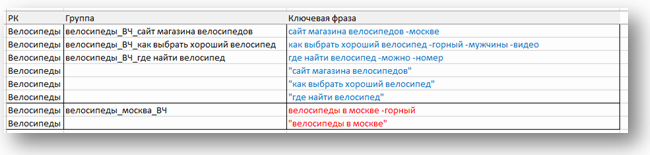
ВЧ-группы удобно выделять цветом (например, синим отмечать группы с несколькими ВЧ-фразами, а красным — с одной). Это поможет на этапе написания объявлений.
Группы с несколькими ВЧ-словами также стоит разбить. Это легко сделать через формулу сцепки в Excel:
Вообще, отмечать группы цветом удобно на каждом этапе работы. Например, отминусовали группу — отметили жёлтым. Сгруппировали — отметили зелёным. Перенесли в Excel — отметили синим. Это поможет при групповой работе над проектом.
После того, как мы полностью скопировали наше сгруппированное семантическое ядро из Кey Collector в Excel, можно приступать к объявлениям.
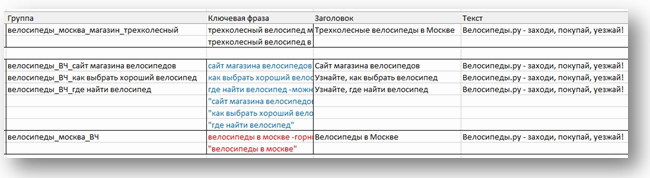
Добавим вторые варианты объявлений. Для этого копипастим строки, содержащие название группы и само объявление:
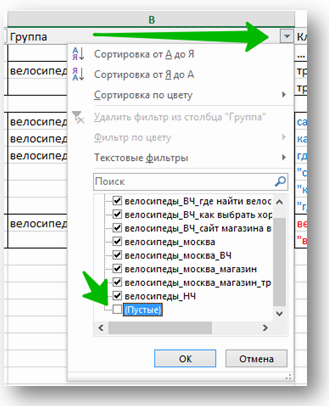
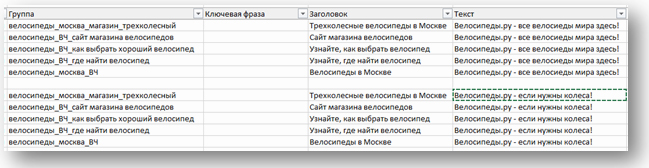
После добавления доп. объявлений заполняем копипастами все недозаполненные строки — и наши группы объявлений под заливку почти готовы. Останется доработать файлы в соответствии с форматами «Яндекса» или Google. Победа!
Спасибо всем, кто дочитал до конца. Если статья оказалась для вас полезной, смело делитесь материалом со своими коллегами. Если бесполезной — тоже не держите в себе, пишите. Остались вопросы? Спрашивайте в комментариях.
Авторы статьи:
Анастасия Якунина, production-менеджер в Adventum,
Артур Семикин, performance-менеджер в Adventum.
Первую часть руководства — Как проработать семантическое ядро с помощью Key Collector (подбор масок, добавление и парсинг в Key Collector) — читайте тут.
Мнение редакции может не совпадать с мнением автора. Если у вас есть, что дополнить — будем рады вашим комментариям. Если вы хотите написать статью с вашей точкой зрения — прочитайте правила публикации на Cossa.
Популярные новости
17 января 2025, 10:43
16 января 2025, 13:28