Как оценить качество данных об аудитории
Фундаментальная эволюция дисплейной рекламы, ускоренная появлением технологии торгов в реальном времени (RTB) — это концепция аудиторных закупок. Мы привыкли покупать паблики, основываясь на характеристиках посетителей конкретного сайта. Сегодня появилась возможность выбирать, каких пользователей купить, независимо от того, какие сайты они посещают.
Аудиторные закупки требуют, чтобы у вашей рекламной платформы был доступ к таргетированным данным, позволяющим за считанные доли секунды купить нужные показы. Вооружившись данными об аудитории, можно настроить таргетинг по самым разным характеристикам: демографическим, психографическим, поведенческим. В результате вы получаете более актуальные для целевой аудитории кампании.

Существуют пять основных критериев, по которым можно судить о качестве данных. На одном конце спектра — непрозрачные и слабые данные сомнительной ценности, на другом — данные, которые прозрачны, надежны и обладают высокой ценностью как для издателей, так и для маркетологов.
Эффективная реклама с кешбэком 100%
Таргетированная реклама, которая работает на тебя!
Размещай ее в различных каналах, находи свою аудиторию и получай кешбэк 100% за запуск рекламы.
Подключи сервис от МегаФона, чтобы привлекать еще больше клиентов.
Реклама. ПАО «МегаФон». ИНН 7812014560. ОГРН 1027809169585. ERID: 2W5zFGNJXGC.
Источник: откуда приходят данные?
Знание того, откуда берутся данные об аудитории, является первым шагом в оценке их качества. Данные в зависимости от того, кому они принадлежат, делятся на:
- 1st party data — ваши собственные данные. Если вы рекламодатель, то это сведения, которые вы собираете о посетителях веб-сайтов и клиентов CRM-систем. Если вы издатель, то это данные, которые вы получаете непосредственно от посетителей вашего сайта. 1st party data обладают самым высоким качеством. Они лучше других данных хотя бы потому, что не будут стоить вам ни копейки.
- 2nd party data — данные рекламной активности, которые принадлежат кому-то, с кем вы взаимодействуете. Например, если вы рекламодатель, заключивший сделку с издателем, то вы будете использовать данные своего партнера в качестве 2nd party data. Такие данные очень близки по своему качеству к 1st party data, но их ценность зависит от уровня прозрачности.
- 3rd party data — сторонние данные, которые, как правило, имеют неизвестное происхождения. В редких случаях поставщик таких данных может указывать на то, откуда они «родом», но обычно это нельзя проверить. Сторонние данные чаще всего поставляются платформами управления данными (DMP), которые группируют и упорядочивают аудиторные данные, поступающие из разных источников: от поставщиков, издателей и других игроков рынка. В связи с тем, что 3rd party data нельзя назвать прозрачными, потому как поступают они не из надежного источника, они преимущественно невысокого качества. Их «свежесть» или возраст часто неизвестная величина, большинство поставщиков такой информации полагаются на куки браузеров как на основной механизм получения сведений об аудитории.
Механизм: как можно использовать данные?
Еще один важный аспект, который нужно учитывать при оценке качества данных — какая технология лежит в их основе. Основываются ли они на cookies из браузера пользователя или технологии «цифровых отпечатков»? А может эти данные получены из идентификатора пользователя закрытого приложения или платформы? Такие знания непосредственно влияют на отслеживание и охват целевой аудитории.
- Собственная база данных — 1st party data, которые связаны с учетными записями пользователей на собственных платформах или приложениях. Такими внутренними базами данных располагают компании Facebook, LinkedIn, Twitter, Google, Amazon, Microsoft и другие. Подобные сведения являются наиболее качественными, потому как они не основаны на cookies.
- Цифровые отпечатки. Снятие цифровых отпечатков — относительно новая технология, которая собирает все уникальные атрибуты того или иного компьютера: IP-адрес, разрешение экрана, версию браузера, установленные в браузере плагины, библиотеку шрифтов, часовой пояс и многое другое. Все эти детали имеют цифровой отпечаток, который, если верить Фонду Электронных Рубежей (Electronic Frontier Foundation), является уникальным на 94%. Это очень перспективная технология, которая, как считают многие, более надежна, чем использование куки. Однако пока это вопрос будущего.
- Куки. Долгое время куки служили стандартным механизмом, приводившим в действие дисплейную онлайн рекламу, в частности, поведенческий компонент таргетинга, особенно в пространстве RTB и DMP. Тем не менее, эффективность cookies постепенно снижается, на горизонте появляется множество угроз: защитники неприкосновенности личных данных, государственное регулирование, претензии компаний-производителей браузеров и программного обеспечения. Срок жизни 50–75% cookies составляет всего 30 дней, что делает данный механизм таргетинга особенно ненадежным. Многие участники экосистемы рекламных технологий активно готовятся к отказу от использования cookies для сбора данных.
Методология: как происходит сбор данных?
Данный критерий напрямую влияет на точность данных. Обычно выделяют три способа сбора данных:
- Анкетные данные. Добровольно предоставлены посетителями, пользователями или клиентами (сведения из профиля, регистрационные данные или результаты опросов). Такие данные могут включать сведения о возрасте, поле, доходах домохозяйства, интересах, языке, вероисповедании и многом другом. Это самые качественные данные в силу надежности их источника. Информация поступает из первых рук, хотя кто может гарантировать, что люди предоставляют правдивые сведения?
- Предполагаемые данные. Если отсутствует необходимая информация для максимально точного исчисления нужной величины, используется приближенное вычисление, которое позволяет ориентировочно определить значение этой величины. Такая неточная оценка и является источником предполагаемых данных. Этот тип сбора данных подразумевает, что сведения собираются и маркируются таким образом, чтобы можно было сделать предположение о некоторых характеристиках или атрибутах аудитории. Часто такой сбор основан на поведении пользователей во время просмотра страниц сайта. Например, издатель, у которого есть сайт для молодых мам, может создать ряд предполагаемых сегментов данных на основании категорий посетителей сайта: женщин, молодых родителей, посетителей разных возрастов и т. д. Предполагаемые данные не так надежны, как анкетные, но все же достаточно точны.
- Смоделированные данные. Чтобы увеличить размер и масштаб отдельных аудиторных сегментов, многие компании придумали свои собственные методы моделирования характеристик существующей аудитории, основанных на заявленных и предполагаемых данных. Особенностью этого метода, который часто называют «look-alike» или «behave-alike», заключается в том, чтобы найти как можно больше пользователей одного типа. Такой тип данных характеризуется более низким качеством, потому как алгоритмы моделирования зачастую запатентованы и непрозрачны.
Актуальность: каков возраст данных?
Одно из самых недооцененных свойств аудиторных данных — это их актуальность. Очень важно понимать, как давно была приобретена информация, особенно если речь идет о данных, основанных на cookies, потому что это определяет стратегию ведения торгов в рамках любой кампании.
Несколько лет назад компания Dapper, которая занимается разработкой решений для оптимизации и показа баннерной рекламы (сейчас является собственностью Yahoo), провела исследование, в ходе которого выяснилось, что в рамках кампаний ретаргетинга больше всего конверсий происходило в течение первых 7 дней. В итоге был сделан вывод, что повышать ставки во время торгов нужно именно в этот отрезок времени.
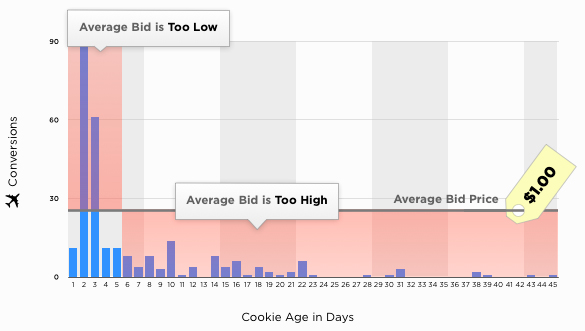
Это исследование показало, что ценность аудитории наиболее высока в течение первой недели. Это влияет как на стратегии проведения торгов, так и, что более важно, на оценку качества данных. First-party data дают самое четкое представление о возрасте, а поэтому и о ценности аудитории.
Цена: сколько стоят данные?
С практической точки зрения одним из самых важных факторов, которые следует учитывать при оценке аудиторных данных, является цена сегмента. Стоимость данных важна, потому что она оказывает непосредственное влияние на фактический исход кампаний. Нужно помнить, что понятие «цена данных» применимо лишь в том случае, когда речь идет о 2nd party и 3rd party data.
Стоимость данных должна быть сопоставима с постепенным приростом эффективности, если таковой имеется. Цена может сильно различаться: от 25 центов до 5 долларов за тысячу показов. В целом же эта величина носит произвольный характер: стоимость данных может легко перевесить стоимость рекламы, поэтому очень важно учитывать эту величину в конечных расчетах и всегда убеждаться в том, что та или иная цена целесообразна с коммерческой точки зрения.
Определение фактической эффективности
Предыдущие критерии предназначены для того, чтобы оценить одну из вводных вашей кампании, но единственное, что важно — это результат использования данных. Определение производительности данных — стандартная процедура. Нужно лишь дать ответ на вопрос: привело ли их использование к положительным или отрицательным результатам? Эти результаты можно измерить на основании доходов, конверсий, уровня осведомленности о бренде и других метрик. Это позволит всегда иметь базу для сравнения. Например, если data-driven кампания показала рост эффективности по сравнению с кампанией, при проведении которой не использовались данные, то перевесит ли полученный эффект стоимость аудиторных данных?
Если бы можно было определять эффективность данных об аудитории еще до их покупки, не нужно было бы беспокоиться о критических оценках. К сожалению, единственным способом определить производительность данных является их применение.
Источник картинки на тизере: Benchmark
Популярные новости
19 марта 2025, 14:00
18 марта 2025, 17:31
18 марта 2025, 11:42
17 марта 2025, 15:16
17 марта 2025, 10:59