
Статья из блога АРТИЗАН-ТИМ.
Каким бы продуманным не был сайт, он всегда будет иметь страницы, нежелательные для индексации. Обработка таких документов поисковыми роботами снижает эффект SEO-оптимизации и может ухудшать позиции сайта в выдаче. В профессиональном лексиконе оптимизаторов за такими страницами закрепилось название «мусорные». На наш взгляд этот термин не совсем корректный, и вносит путаницу в понимание ситуации.
Мусорными страницами уместнее называть документы, не представляющие ценности ни для пользователей, ни для поисковых систем. Когда речь идет о таком контенте, нет смысла утруждаться с закрытием, поскольку его всегда легче просто удалить. Но часто ситуация не столь однозначна: страница может быть полезной с т.з. пользовательского опыта и в то же время нежелательной для индексации. Называть подобный документ «мусорным» — неправильно.
Такое бывает, например, когда разные по содержанию страницы создают для поисковиков иллюзию дублированного контента. Попав в индекс такой «псевдодубль» может привести к сложностям с ранжированием. Также некоторые страницы закрывают от индексации с целью рационализации краулингового бюджета. Количество документов, которые поисковики способны просканировать на сайте, ограниченно определенным лимитом. Чтобы ресурсы краулеров тратились исключительно на важный контент, и он быстрее попадал в индекс, устанавливают запрет на обход неприоритетных страниц.
Как закрыть страницы от индексации: три базовых способа
Добавление метатега Robots
Наличие атрибута noindex в html-коде документа сигнализирует поисковым системам, что страница не рекомендована к индексации, и ее необходимо изъять из результатов выдачи. В начале html-документа в блоке <head> прописывают метатег:
![]()
Эта директива воспринимается краулерами обеих систем — страница будет исключена из поиска как в Google, так и в «Яндексе» даже если на нее проставлены ссылки с других документов.

Варианты использования метатега Robots
Закрытие в robots.txt
Закрыть от индексации отдельные страницы или полностью весь сайт (когда это нужно — мы поговорим ниже) можно через служебный файл robots.txt. Прописав в нем одну из директив, поисковым системам будет задан рекомендуемый формат индексации сайта. Вот несколько основных примеров использования robots.txt
Запрет индексирования сайта всеми поисковыми системами:
User-agent: *
Disallow: /
Закрытие обхода для одного поисковика (в нашем случае «Яндекса»):
User-agent: Yandex
Disallow: /
Запрет индексации сайта всеми поисковыми системами, кроме одной:
User-agent: *
Disallow: /
User-agent: Yandex
Allow: /
Закрытие от индексации конкретной страницы:
User-agent: *
Disallow: / #частичный или полный URL закрываемой страницы
Отдельно отметим, что закрытие страниц через метатег Robots и файл robots.txt — это лишь рекомендации для поисковых систем. Оба этих способа не дают стопроцентных гарантий, что указанные документы не будут отправлены в индекс.
Настройка HTTP-заголовка X-Robots-Tag
Указать поисковикам условия индексирования конкретных страниц можно через настройку HTTP-заголовка X-Robots-Tag для определенного URL на сервере вашего сайта.

Заголовок X-Robots-Tag запрещает индексирование страницы
Что убирать из индекса?
Рассмотрев три основных способа настройки индексации, теперь поговорим о том, что конкретно нужно закрывать, чтобы оптимизировать краулинг сайта.
Документы PDF, DOC, XLSНа многих сайтах помимо основного контента присутствуют файлы с расширением PDF, DOC, XLS. Как правило, это всевозможные договора, инструкции, прайс-листы и другие документы, представляющие потенциальную ценность для пользователя, но в то же время способные размывать релевантность страницы из-за попадания в индекс большого объема второстепенного контента. В некоторых случаях такой документ может ранжироваться лучше основной страницы, занимая в поиске более высокие позиции. Именно поэтому все объекты с расширением PDF, DOC, XLS целесообразно убирать из индекса. Удобнее всего это делать в robots.txt.
Страницы с версиями для печатиСтраницы с текстом, отформатированным под печать — еще один полезный пользовательский атрибут, который в то же время не всегда однозначно воспринимается поисковиками. Такие документы часто распознаются краулерами как дублированный контент, оказывая негативный эффект для продвижения. Он может выражаться во взаимном ослаблении позиций страниц и нежелательном перераспределении ссылочного веса с основного документа на второстепенный. Иногда поисковые алгоритмы считают такие дубли более релевантными, и вместо основной страницы в выдаче отображают версию для печати, поэтому их уместно закрывать от индексации.
Страницы пагинацииНужно ли закрывать от роботов страницы пагинации? Данный вопрос становится камнем преткновения для многих оптимизаторов в первую очередь из-за диаметрально противоположных мнений на этот счет. Постраничный вывод контента на страницах листинга однозначно нужен, поскольку это важный элемент внутренней оптимизации. Но в необработанном состоянии страницы пагинации могут восприниматься как дублированный контент со всеми вытекающими последствиями для ранжирования.
Первый подход к решению этой проблемы — настройка метатега Robots. С помощью noindex, follow из индекса исключают все страницы пагинации кроме первой, но не запрещают краулерам переходить по ссылкам внутри них. Второй вариант обработки не предусматривает закрытия страниц. Вместо этого настраивают атрибуты rel=”canonical”, rel=”prev” и rel=”next”. Опыт показывает, что оба этих подхода имеют право на жизнь, хотя в своей практике мы чаще используем первый вариант.
Страницы служебного пользованияТехнические страницы, предназначенные для административного использования, также целесообразно закрывать от индексации. Например, это может быть форма авторизации для входа в админку или другие служебные страницы. Удобнее всего это делать через директиву в robots.txt. Документы, к которым необходимо ограничить доступ, можно указывать списком, прописывая каждый с новой строки.
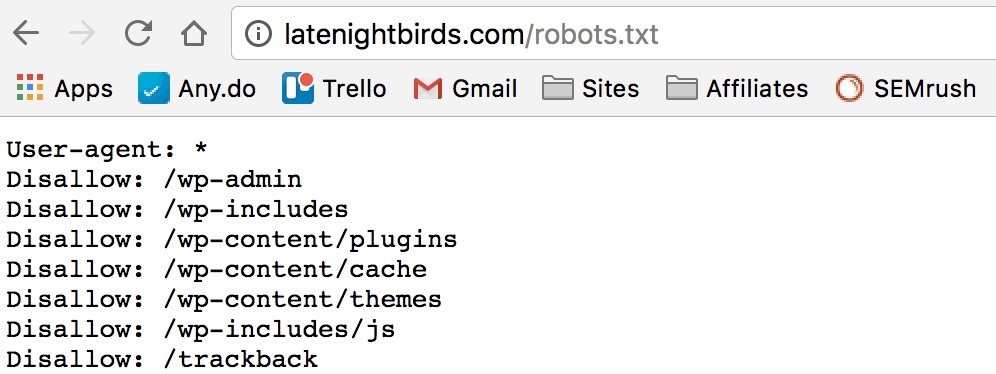
Директива в robots.txt на запрет индексации всеми поисковиками нескольких страниц
Речь идет об элементах, которые ориентированы на уже существующих клиентов, но не представляют ценности для остальных пользователей. К ним относят: страницы регистрации, формы заявок, корзину, личный кабинет и т.д. Индексацию таких элементов целесообразно ограничить как минимум из соображений оптимизации краулингового бюджета. На сайтах электронной коммерции отдельное внимание уделяют закрытию страниц, содержащих персональные данные клиентов.
Закрытие сайта во время технических работСоздавая сайт с нуля или проводя его глобальную реорганизацию, например перенося на новую CMS, желательно разворачивать проект на тестовом сервере и закрывать его от сканирования всеми поисковыми системами в robots.txt. Это уменьшит риск попадания в индекс ненужных документов и другого тестового мусора, который в дальнейшем сможет навредить поисковому продвижению сайта.
Заключение
Настройка индексирования отдельных страниц — важный компонент поисковой оптимизации. Вне зависимости от технических особенностей каждый сайт имеет документы, нежелательные для попадания в индекс. Какой контент лучше скрывать от роботов и как это делать в каждом конкретном случае — мы подробно рассказали выше. Придерживаясь этих рекомендаций, вы оптимизируете ресурсы поисковых краулеров, обеспечите быстрые и эффективные обходы приоритетных страниц, и что самое важное — обезопаситесь от возможных проблем с ранжированием.
Читайте по теме:
Как оптимизировать страницы категорий онлайн-магазинов?
SEO-оптимизация главной страницы интернет-магазина. Подробное руководство