Лента рекомендаций и ИИ: почему языковые модели на старте знают о покупателях больше, чем вы думаете
Нет данных — нет проблем: как языковые модели формируют ленту рекомендаций на старте.

Почему магазинам не стоит бояться подключать рекомендательные системы сразу после запуска сайта и при чём тут большие языковые модели (LLM)? Эксперты ООО «Сбер Бизнес Софт» разбираются в том, какая информация о покупателях потребуется, чтобы корректно настроить ленту и как работают подобные алгоритмы.
Холодный старт и лента рекомендаций: чего ожидать владельцам интернет-магазина
Лента рекомендаций — хороший инструмент для увеличения продаж и улучшения взаимодействия с покупателями. Внешне всё просто: магазин с помощью алгоритмов анализирует предпочтения и поведение покупателей, предлагая им товары, которые могут их заинтересовать. Это не только повышает шансы на покупку, но и укрепляет лояльность, поскольку клиенты чувствуют, что предложения адаптированы лично для них.
Эффективная реклама с кешбэком 100%
Таргетированная реклама, которая работает на тебя!
Размещай ее в различных каналах, находи свою аудиторию и получай кешбэк 100% за запуск рекламы.
Подключи сервис от МегаФона, чтобы привлекать еще больше клиентов.
Реклама. ПАО «МегаФон». ИНН 7812014560. ОГРН 1027809169585. ERID: 2W5zFGNJXGC.

Например, девушка просматривает летние платья и магазин ей показывает подходящие аксессуары: солнцезащитные очки, босоножки, SPF-крем. Это улучшает шопинг, делая его более удобным и приятным.

Но как посоветовать релевантные продукты, когда вы только запустили сайт и ничего не знаете о предпочтениях и поведении пользователей? Это основная проблема холодного старта. Она решается по мере накопления истории взаимодействия с товарами. Сложность в том, что на сбор необходимого массива информации уходит много времени, в течение которого интернет-магазин упускает потенциальную прибыль.
Есть несколько вариантов действий в этом случае. Можно вручную подобрать сопутствующие товары или категории к каждому продукту и «скормить» эти данные алгоритму. Такая разметка потребует перераспределения ресурсов компании и многих часов ручного труда специалистов. Кроме того, при каждом обновлении каталога разметка устаревает: новые товары могут не попасть в списки алгоритма или сами остаться без рекомендаций. А ещё из-за человеческого фактора ручная разметка часто оказывается неточной или содержит ошибки.
Более современный подход к внедрению систем товарных рекомендаций на сайтах — использование больших языковых моделей, или Large Language Models (LLM). Они используют общие стратегии, основанные на языковых шаблонах, которые свойственны большинству пользователей.
Как использование LLM решает проблему холодного старта
LLM — это продвинутый тип искусственного интеллекта, который специализируется на понимании и генерации текста на естественном языке. Эти модели обучаются на огромных объёмах текстовых данных, что позволяет им улавливать тонкости языка, идиомы и контекст. По сути, LLM умеет «разговаривать», «писать» и даже «думать» в некотором роде по-человечески.
Когда мы говорим о рекомендательных системах, важны несколько особенностей. Во-первых, большие языковые модели умеют находить связи между словами. Например, между ноутбуком, мышью и внешним жёстким диском, которые нередко упоминаются в одном контексте.
Во-вторых, LLM использует общие данные о предпочтениях покупателей, об истории покупок, основных трендах. Эту информацию языковая модель получает из открытых источников: сайтов с отзывами, исследований, социальных сетей.
Чтобы улучшить рекомендации, используется метод Retrieval-Augmented Generation (RAG), или генерация с учетом дополнительно найденной информации. Суть в том, что обученную модель дополняют специальной базой знаний. Последняя разбита на куски, или «чанки» (англ. chunks). Те из них, что близки по смыслу, передаются модели в тот момент, когда она получается запрос от пользователя.
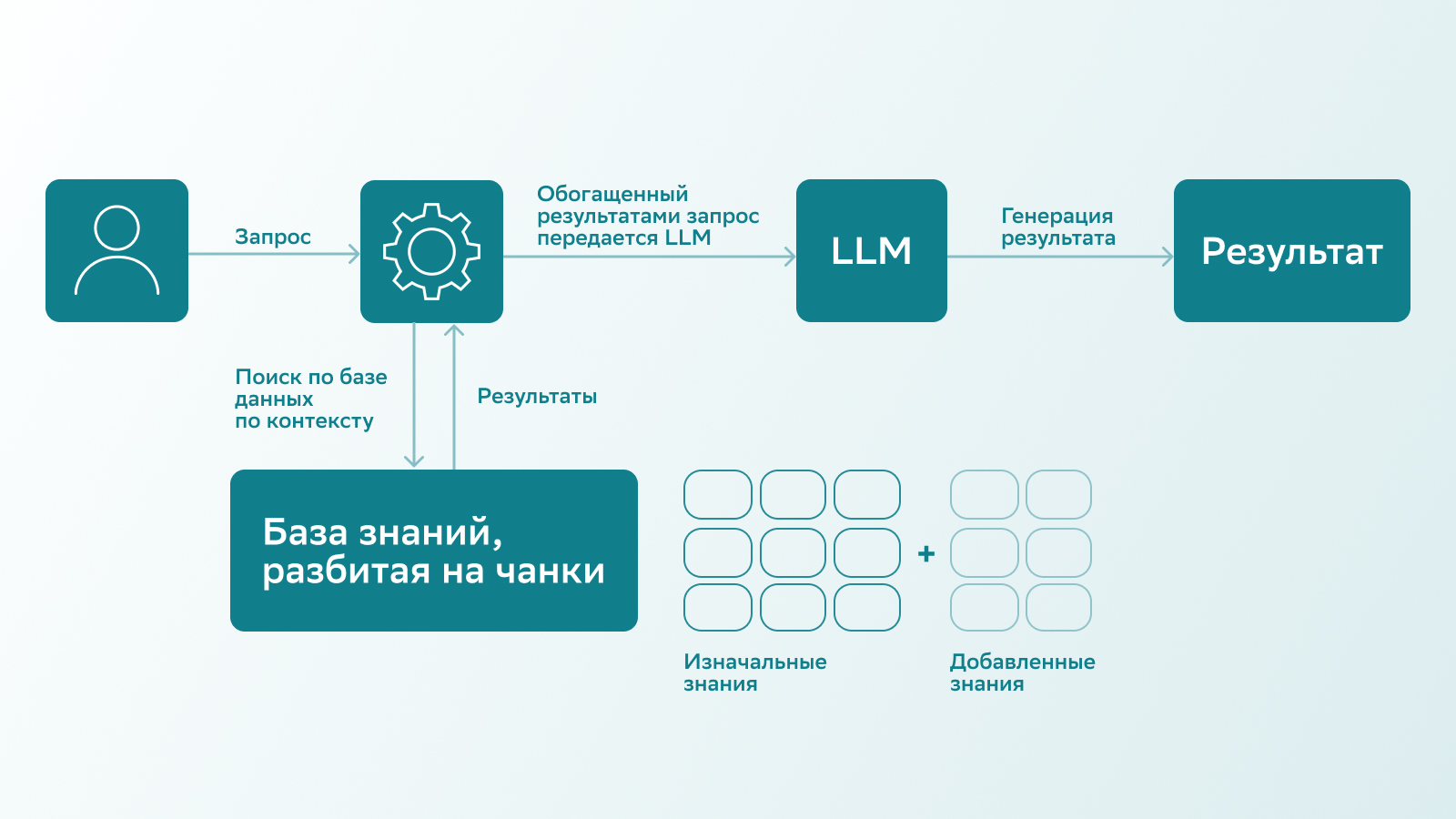
Схема работы RAG-метода
RAG-метод позволяет добавить в модель информацию, необходимую для предоставления более точных рекомендаций, и избежать классического дообучения, которое требует огромных массивов высококачественных данных, больших затрат вычислительных ресурсов и, конечно, времени.
Использование больших языковых моделей и калибровка их знаний методом RAG позволяет быстро запускать рекомендательные системы на сайтах. Всё это позволяет избежать проблемы холодного старта при подключении новых клиентов к лентам рекомендаций.
Технология настройки: отбор, промпт, калибровка
Чтобы заказчики могли получать пользу от рекомендательных систем сразу же, а не ждать накопления статистики о частоте совместных покупок, можно интегрировать свои ленты рекомендаций с LLM. Это позволит автоматизировать процесс разметки категорий товаров и существенно сократить время на формирование рекомендаций сопутствующих товаров на начальных этапах.
Процесс настройки такой системы можно описать в трёх шагах.
Отбор товаров-кандидатов. Сначала нужно определить продукты, которые могут попасть раздел «сопутствующих». Для этого выполняется поиск по кластерным и семантическим сходствам в категориях товаров. Если проще: анализируются данные о покупках и выявляется то, что люди часто приобретают вместе. Алгоритм улавливает семантическую связь. Например, если в описании одного товара указано «кухонный комбайн», а другого — «блендер», он объединит их в одну группу кухонной техники.
Если необходимо найти товары для категории «Рубашки», то рекомендательные сервисы определяют связанные с этим товаром характеристики, например, сорочки и блузки. Такой подход позволяет более точно определить, какие продукты лучше всего подходят для каждой категории и оптимизировать процесс отбора, сокращая количество товаров, которые не соответствуют требованиям.
Проведение разметки. Из предварительно отобранных кандидатов система составляет список сопутствующих категорий товаров на основе промпта — детального описания задачи. В нём содержится роль языковой модели, задачи, которые нужно выполнить, критерии, инструкции и формат выходных данных.
Вот так может выглядеть промпт:
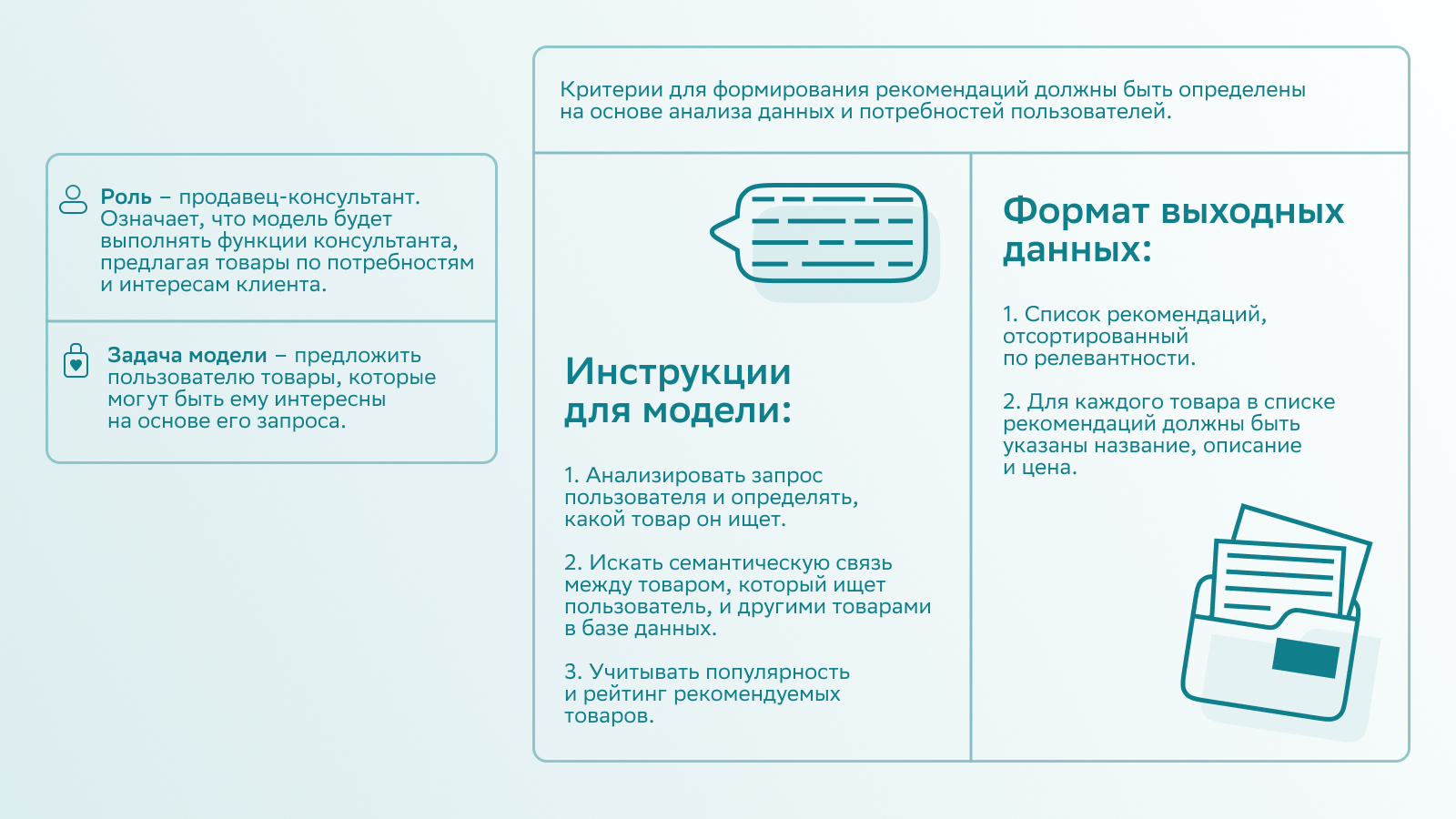
LLM для рекомендации товаров использует своё понимание мира и покупательских предпочтений. К примеру, если покупатель ищет классические брюки, модель использует информацию о том, что их обычно носят на работу или на формальные мероприятия, и предложит брюки, которые соответствуют этим требованиям. Такой подход позволяет решить задачу без сбора обучающего датасета для каждого конкретного магазина.
Так, например, крупная сеть строительных гипермаркетов за счёт использования рекомендаций повысила конверсию в покупку в 2 раза. Для этой ниши актуальны два типа рекомендательных алгоритмов: «Похожие» и «Сопутствующие товары». Алгоритмы анализируют прошлые продажи и характеристики товаров, чтобы персонализировать рекомендации под пользователя. В итоге средняя стоимость покупок на сайте выросла в 5 раз, а рост ROI составил 500% за полгода.
Проверка и корректировка результата. На старте системе требуется калибровка, поэтому рекомендации, предоставленные нейросетью, проверяются людьми с помощью специальных метрик: точность, полнота и так далее. Они позволяют оценить, насколько хорошо модель машинного обучения формирует рекомендации.
Если рекомендации не соответствуют критериям, команда корректирует их. Для этого можно составить промпт заново, изменив его параметры, или использовать дополнительные данные. Например, можно добавить информацию о предпочтениях или о том, какие товары были куплены вместе.
В итоге внедрение LLM в рекомендательные системы улучшает пользовательский опыт и значительно сокращает затраты на маркетинг, оптимизируя рекламные кампании. Особенно это актуально при холодном старте. С помощью больших языковых моделей компании могут также предсказывать будущие тенденции, адаптируясь к изменениям рынка в реальном времени.
Мнение редакции может не совпадать с мнением автора. Ваши статьи присылайте нам на 42@cossa.ru. А наши требования к ним — вот тут.
Популярные новости
1 апреля 2025, 12:38
1 апреля 2025, 10:00
31 марта 2025, 17:42
31 марта 2025, 13:52
31 марта 2025, 12:13